Using Backup Sets
Hot copies may be organized into backup sets. Backup sets provide a convenient mechanism for identifying hot copies and maintaining metadata information locally while allowing data to be compressed and/or moved to an alternative (typicaly, offsite) storage location. Backup sets are also required in order to take advantage of the incremental hot copy functionality and/or journal hot copy for point-in-time restore.
-
A new backup set will be created when using full hot copy.
-
Backup sets are required if using incremental or journal hot copy.
-
It is up to you to specify the backup set to use (usually the one created by the most recent full backup).
-
Backup Set Directory
A backup set is a directory created when initiating a full hot copy on a given SM.
The full hot copy is stored into a subdirectory in the backup set called full.
Once created, zero or more journal hot copies and/or zero or more incremental hot copies may be stored into the latest backup set created for each SM.
Journal and incremental hot copies are stored in numbered subdirectories such as 1.inc or 2.jnl.
Subdirectories containing hot copies are called hot copy elements.
Inside each hot copy element (sub-directory) are two directories, control and data.
Here is an example of the directory structure in a backup set containing one full hot copy, two incremental hot copies, and two journal hot copies.
/tmp/hotcopy/2017-12-18
├── 1.inc
│ ├── control
│ └── data
├── 1.jnl
│ ├── control
│ └── data
├── 2.inc
│ ├── control
│ └── data
├── 2.jnl
│ ├── control
│ └── data
├── full
│ ├── control
│ └── data
├── tmp
└── state.xmlWhile a backup set is being used by hot copy commands, the control directories must not be modified, moved or deleted otherwise the backup set becomes unusable.
However, if you risk running out of space on your backup volume, you can compress and/or move the data directories.
Note that the backup set cannot be used with nuoarchive restore until the data directories hve been restored and/or uncompressed.
|
If you no longer need a backup set you can delete it, provided it is no longer being used by any hot copy.
Backup process
Backups work as follows:
-
Full hot copy produces a consistent copy of an SM including both the archive and any outstandiing journal files.
-
Incremental hot copy produces a space-efficient copy of all changes since the most recent full or incremental hot copy on the current backup set.
-
Journal hot copy copies changes since the most recent journal hot copy to enable point-in-time restore.
Backup Set Naming
It is highly recommended that each backup set be named with the database it was created from and with the date or date and time it was created. NuoDB tools do not rely on this naming convention, but it has the following advantages:
-
Simplifies management of backup sets, especially if you have (or may have) more than one database.
-
Provides a way to search for full and incremental hot copies of interest.
-
Makes it easier to find the backup set to use for a timestamp of interest with point-in-time restore.
| After execution of a hot copy operation, NuoDB does not have a record of the hot copy destination directory. It is up to you to track and manage database copies, hence the need for a good naming convention. |
Backup Set Location
The backup sets created by executing full hot copy on a given SM can be stored wherever you like, but it is recommended to keep them together, such as on a dedicated, fast volume. In particular, if using journal hotcopy, backups sets should be created in the same parent directory.
Backup sets are typically local to the host where the SM is running to ensure fastest disk access. Backups may be made to a network attached disk (often the only option in a Cloud or Kubernetes deployment) but beware network overhead reducing the speed of disk writes.
Once a new backup set has been successfully created, all subsequent incremental and journal hot copies should specify the same backup set until the next full hot copy has created a new backup set and finished successfully.
Starting a New Backup Set
Start a new backup set periodically to ensure that older backup sets can be deleted later to conserve space and comply with data retention requirements. Restoration time is proportional to the number of incremental or journal hot copies that must be processed.
There is a trade-off here:
-
Running a full hot copy takes time and requires as much backup space as the original archive and journal. You don’t want to do it too often.
-
Running incremental and journal hot copies requires only space proportional to the number of changes. However restoration takes longer as the number of incremental/journal hot copies increases.
New backup sets should also be started periodically in case there is a data corruption in the storage where backups are stored, making the backup set unusable.
Managing Backup Sets
Once a backup set has been created, by running a full hot copy, it can be used for incremental and journal backups. At some point you will want to start a new backup set, as described above. Here is the workflow:
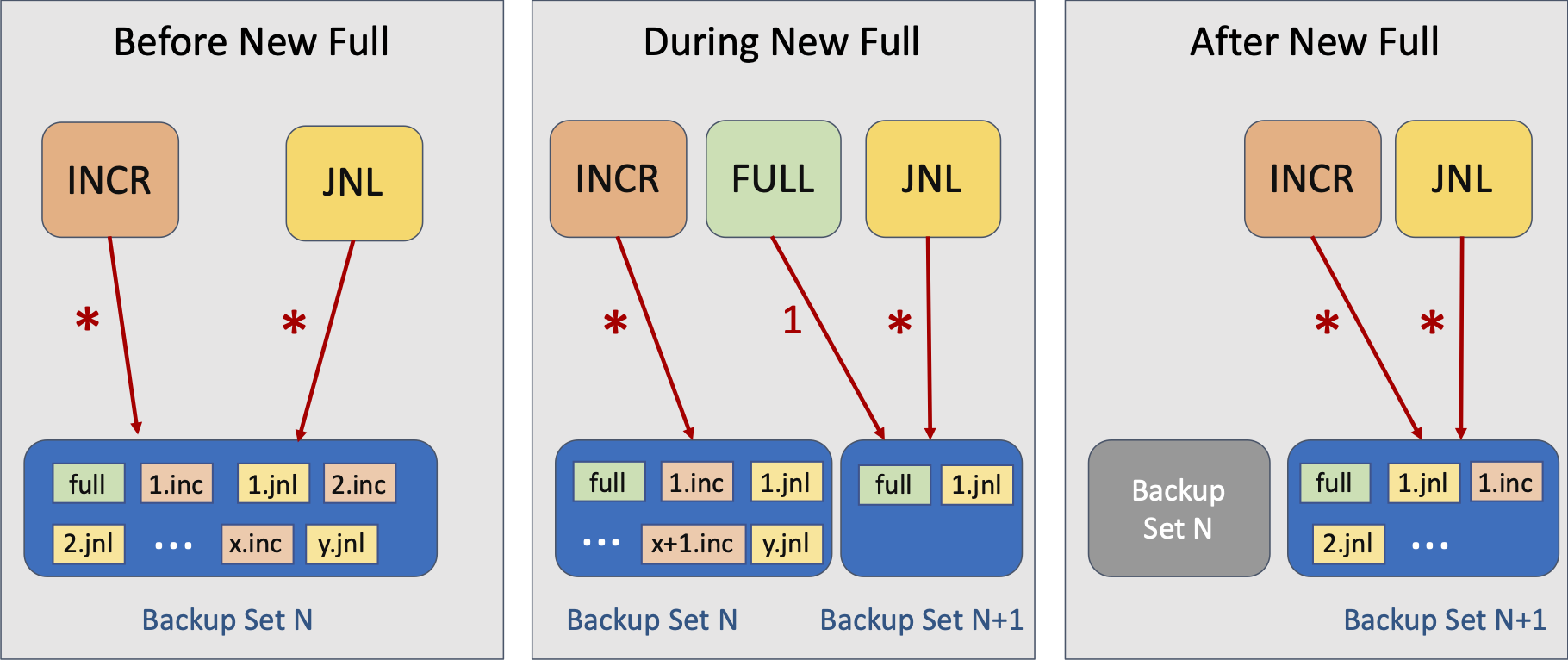
- Backup Set Exists
-
Incremental and/or journal backups written periodically to the backup set according to your preferred schedule.
- Creating New Backup Set
-
A full hot copy is run creating a new backup set. This can take time to complete. While the full hot copy is running:
-
Scheduled incremental backups still run against the previous backup set.
-
Scheduled journal backups use the new backup set immediately, even though the full hot copy is still running.
-
The journal backup can run as soon as the full backup has initalized the new backup set (the full backup does this by writing metadata as its first step).
-
For this reason, a point-in-time restore to a time during this period, needing
1.jnlfromBackup Set N+1(middle diagram), will also require the previous backup set (Backup Set N). See here for details.
-
-
- New Backup Set Exists
-
This becomes the current backup set. Incremental and/or journal backups are now written periodically to this backup set according to your preferred schedule. The previous backup set can be compressed and/or copied to off-host storage unless you might need a point-in-time restore (in which case it must be kept to allow for the special case where two backup sets are required).
Deleting Backup Sets
It may be desirable to delete old hot copies to save space, or to comply with data retention requirements (such as moving them to long-term, off-site storage for regulatory compliance).
Considerations:
-
The minimum unit of deletion is the backup set.
-
A backup set cannot be moved to alternative storage, such as offsite, until the next backup set has been created.
-
For example, if you are performing a full backup daily, once the full hot copy creating today’s new backup set has finished running successfully, then yesterdays backup set can be compressed and/or moved.
-
If using journal hotcopy and may wish to perform a point-in-time restore, you must keep at least the two most recent backup sets.
-
-
It is usual to delete backup sets in order from oldest to newest.
-
You may choose to keep more than one backup set on the SM host to allow faster restoration in the event of failure.
-
There is a trade-off between the speed of restoration (not having to copy a backup set back from offline storage) versus the extra storage space needed on the backup volume.
-
The target hot copy directory should not be removed or renamed during a hot copy operation.
If that occurs, the SM will exit with the following error message: Unable to create archive directory: No such file or directory.
|