Data Access and Replication
How Does NuoDB Work?
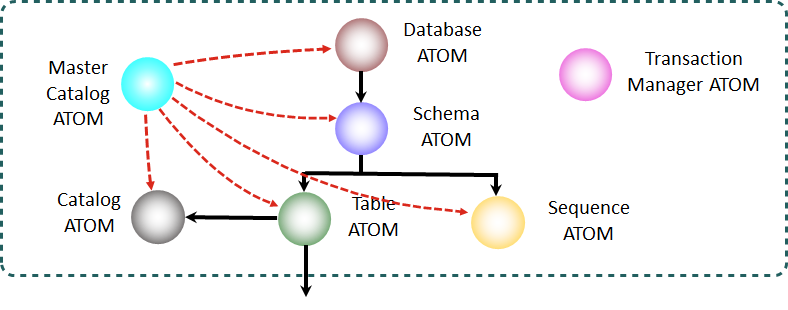
The Catalog Atoms are key to how NuoDB works.
A catalog contains both relationship and runtime information.
-
The relationship data is the relationship between objects in the domain - what tables belong to the database, what rows and indexes do the tables have, and so on.
-
The red arrows in the diagrams below are the relationship information.
-
-
The runtime information keeps track of which engine (TE or SM) holds a copy of a given atom - these processes are called the atom’s peers.
When a TE starts up, it loads the Master Catalog and its relationship data allows it to find all the schemas, sequences and tables in the database.
When the TE receives a SQL query:
-
It loads the Table atom(s) and corresponding Catalog(s) for the table(s) in the query.
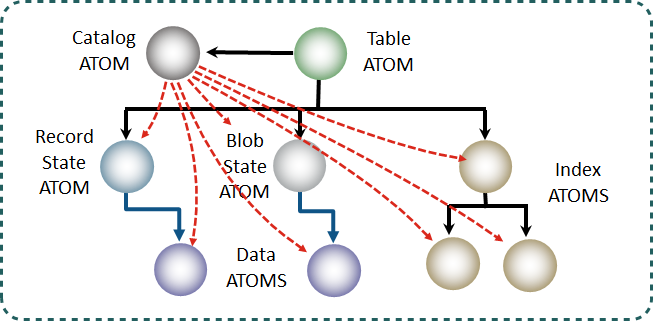 Figure 2. Database Catalog Atom
Figure 2. Database Catalog Atom -
The runtime information in a table’s Catalog atom tells the TE where other atoms (if any) for this table can be found.
-
Using this data, the TE can request the atoms it needs to fulfill the query (rows from the table, index structures, and so on) either from other TEs or an SM.
-
As it loads atoms, the TE becomes a peer for those atoms and is added to the runtime information for the relevant Catalogs.
-
After the first time, these atoms are cached and do not need to be re-fetched for subsequent queries.
Fetching An Atom
This diagram shows the simple case of fetching a single Data Atom to access more rows from a table.
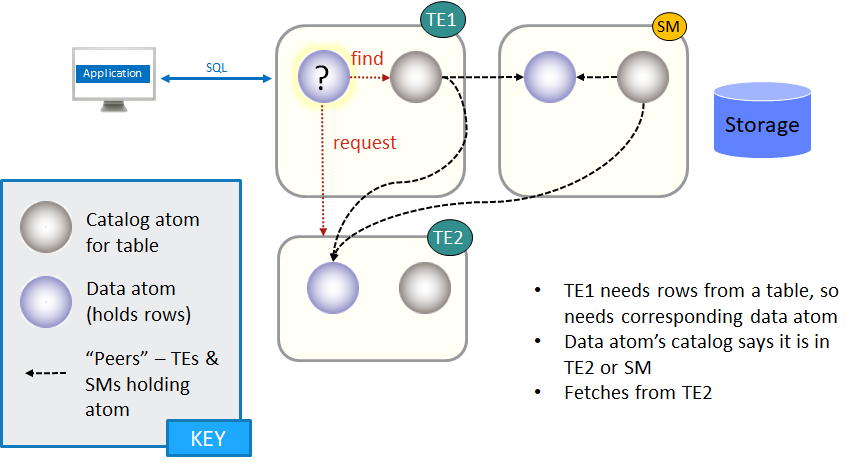
In general, a TE is more likely to get data from another TE rather than from an SM because using the SM might involve a disk read.
Replicating Changes
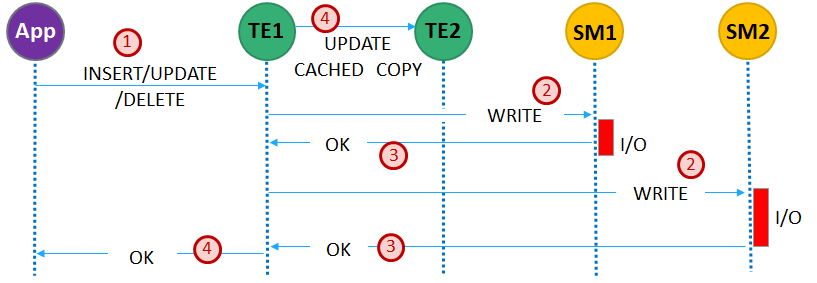
Changes to data must be committed by all running SMs for the transaction to be complete. The (somewhat simplified) workflow is illustrated here (see Commit Protocol for full implementation.)
-
Request sent to TE1.
-
Modified atom diffs committed to SMs.
-
The app waits for acknowledgments from each SM.
-
TE1 tells other TEs (TE2) to update their cached copy (from the same diffs) and acknowledges the client.
As before, the catalog data tells TE1 which TEs (TE2) have the same data cached.
What happens to the copy of the atom on TE2 during the transaction on TE1 depends on the isolation level of the transaction in TE1.
READ COMMITED-
The copy in TE2 is locked to avoid concurrent modification. The lock is released once the transaction-committed message is received and the atom is updated.
CONSISTENT READ-
The atom is not locked because consistent read transactions don’t take locks. However, if the consistent read transaction (
tx1) on TE1 attempts to modify the atom, it will fail (with a concurrent modification exception) if the copy on TE2 was modified beforetx1committed.
For more details on isolation levels, see Description of NuoDB Transaction Isolation Levels.