High-level SQL Pipeline
Executing Queries
NuoDB’s SQL processing runs inside the TEs. Whenever a query is received for the first time, it has to be processed into a format that the SQL Engine can execute. This process is known as Query Compilation. It includes all the phases a query goes through, from the textual representation (SQL) to the Execution Operator Tree (more commonly known as the Query Plan).
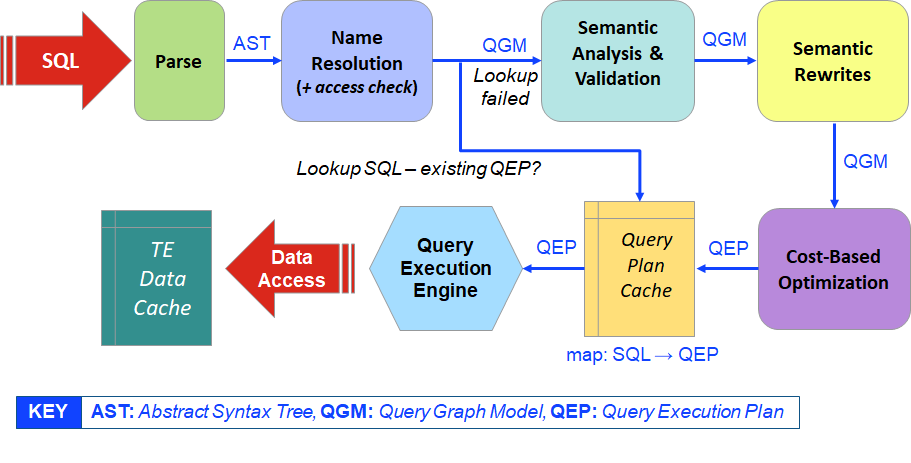
The processing steps are as follows:
- Parsing
-
Converts the query text into a syntax tree.
- Name Resolution
-
Binds names in the syntax tree to the named objects in the metadata catalog such as table names, sequence names, and so on. Also, checks the user has correct access permissions for the objects in the query.
- Semantic Analysis & Transformation
-
This phase validates that the query is semantically correct and builds a new intermediate representation — the Query Graph Model (QGM).
- Semantic Rewrites
-
This phase aims to make the query run faster by rewriting it to semantically equivalent forms. Examples are merging views or calculating constant expressions upfront. These changes reduce the number of operations executed to evaluate the query but don’t change the outcome (its semantics stay the same).
- Cost Based Optimization
-
This phase decides the "optimal" way a query can be executed. Generates the execution operator tree, otherwise known as the Query Execution Plan (QEP).
- Query Plan Cache
-
Newly created plan is added to the cache of previously optimized QEPs.
- Query Execution Engine
-
Runs the query, fetching the data it needs as it goes. Data is either used from the TE’s data cache or fetched from other engines as needed.
The basic process is therefore:
-
Parse the query, check if its plan is in the cache and if so run it.
-
Otherwise, compile the query, put its plan in the cache and then run it.
Query Plan Cache
When a query is first submitted, the TE looks it up in its Query Plan Cache (sometimes referred to as the Query Statement Cache). If found, the plan can be run straight away, avoiding the overhead of Query Compilation.
The cache is keyed on the actual SQL statement (but see first bullet below). A small change to the SQL will force a recompilation which is useful during testing.
-
Note that query-plan lookup occurs after name resolution, so if the table(s) used by the query have changed, a cache-miss occurs, forcing recompilation. User access to the table(s) in the query are checked each time also. The following force recompilation:
-
Modifying any of the objects (tables, views, user-defined functions or sequences) used by the query - for example, the columns being queried may have changed type, been renamed or deleted.
-
Modifying, adding or dropping any index(es) on the table(s).
-
If the number of rows in a table has changed significantly and better/different optimizations may be required.
-
As there are typically multiple TEs, each has its own Query Plan Cache. The cache relies on the fact that, in general, the same query will likely be submitted more than once to the same TE. NuoDB’s load-balancing capability can be used to force connections to the same TE or subset of TEs.
Manually getting the explain plan for a query using SQL EXPLAIN does not use the Query Plan Cache, the query is compiled every time.
Be careful when debugging because the plan you see running EXPLAIN, may not be the plan used from the cache.
|
The cache can be controlled by setting the System Property MAX_STMT_CACHE_SIZE which defaults to 500 queries (per TE).
Setting the cache size to 0 will empty and disable the Query Plan Cache.
Behind the scenes, the same garbage collection process that removes old or obsolete atoms from the TEs data cache, also periodically cleans out the query plan cache.