Using Hot Copy Successfully
When you invoke hotcopy to create a copy of a database’s current state, the copy contains both the archive (database data) and the journal(s) of that database.
The database state stored in this archive-plus-journal is transactionally consistent and contains the state of the archive at approximately the time when the hot copy finished running.
You can then use this copy to create a new archive and start a new Storage Manager (SM).
Creating an archive from the backup may require the NuoDB Archive utility (nuoarchive).
| After execution of a hot copy operation, NuoDB does not have a record of the hot copy destination directory. It is up to you to track and manage database copies and to manage whatever offline storage you decide to use. |
With the exception of simple hot copy (see below), the destination directory where the backup is stored is a backup set.
Recommendations:
-
Design site-specific guidelines for naming conventions for hot copy destination directories - we suggest incorporating the backup creation date into the directory name.
-
Post-process hot copy backups in accordance with a backup policy by, for example, compressing them with an external tool and/or moving them to a remote location.
Why Use Hot Copy?
The first thing to remember is that if you are running multiple SMs then you always have (unless there is an outage) multiple up-to-date copies of the database before running any hot copy.
If you lose an SM, you can restart it and it will SYNC from the other SMs to bring itself back up to date (with all changes since it stopped running) becoming usable again.
Hot copy backups are intended for disaster recovery when one or more SMs cannot be restarted, typically due to failure of the underlying hardware and/or failure of all SMs.
Journal hot copy with point-in-time restoration can be used to fix "fat finger" errors, where the data inside the database has got corrupted (for example, a row or table deleted in error).
If at least one SM remains. you can start a brand new SM (perhaps with a new disk and/or a new host) using an empty archive and let it SYNC the entire database from the other SM(s). However, it may be a lot faster to first restore an archive from the latest backup and then restart, reducing SYNC time and overhead.
Types of Hot Copy
- simple
-
A simple hot copy creates an identical copy of the archive in the target directory. This backup can be used directly with
nuocmd create archiveby specifying the--restoredoption.This is the only hot copy option that does not use or create a backup set. For details, see Using Simple Hotcopy.
- full
-
Creates a brand new backup set in the target directory. It contains a complete backup of the source archive, containing both the archive itself and its journal files. This becomes the backup set which you should specify when running future incremental and/or journal hot copies so that backups will be appended into it, until the next full hot copy. See Using Full Hot Copy.
- incremental
-
Using the specified backup set, creates a backup of all changes since the most recent incremental backup (or since the full backup if no incremental backups have yet been taken). Internally NuoDB keeps track of atoms that have changed and only copies changed atoms into the backup set. Using incremental backup is therefore quicker than a full backup and requires less space. See Using Incremental Hot Copy.
- journal
-
Also creates a backup of changes, but does so by making copies of all messages in the journal since the most recent journal backup.
The backed up journals are always added to the most recently created backup set. Unlike an incremental backup, journal backups allow restoration to a specific point-in-time provided it is within a backup set. Journal backup first must be enabled for each SM that wishes to perform it. See Using Journal Hot Copy.
Backup sets cannot be used directly but must be processed by nuoarchive to recreate an archive.
This allows for more control — such as restoration to an earlier state than the most recent backup.
|
Running Hot Copy
Typical usage is to run a full hot copy periodically, perhaps daily or weekly, followed by regular incremental and/or journal hot copies. How often depends on the rate at which your database changes and how up-to-date your backups need to be.
Unix cron could be used, but an enterprise job scheduling or workflow tool is preferred. They have their own fault tolerance and avoid complications if local schedules are lost along with the node that hosts those processes. Examples: BMC Control M, Apache Airflow.
There is a trade-off between using incremental backups to reduce backup times and having so many incremental backups that restoring from the backup starts to take too long (all incrementals have to be processed to restore the archive, so the more there are the longer it takes). However, if you take both incremental and journal hot copies, restoration will try to use any incremental backups first (because they are quicker) and then finish with the journal backups as needed.
When running two or more hot copy commands against a given archive concurrently:
-
It is not possible to run two hot copies of the same type against the same backup set.
-
It is not possible to run a full and incremental hot copy against the same backup set.
-
It is possible to run a journal hot copy against a backup set whose full hot copy is still running once the full hot copy has created and initialized the new backup set (this involves creating metadata and is the first step of a full hot copy).
-
It is possible to run a journal and incremental hot copy against the same backup set concurrently.
-
It is possible to run an incremental hot copy against a previous backup set while a full hot copy is creating the next backup set. This is useful if your full hot copy takes a long time to run, so you can keep backing up into the previous backup set until the new backup set is ready.
-
It is not possible to run a journal hot copy against a previous backup set if the next backup set has been initialized. Once a full hot copy has started, journal backups must be performed against the new backup set. This has implications for backup-set management and restore.
Redundant Hot Copy
It is recommended to run hot copy against more than one SM to ensure redundancy. If the only SM being used for hot copy is offline, no scheduled backups will be taken until the SM is online again and any SYNC (to bring it fully up to date) has completed. (instead you would have to run hot copy manually against any remaining SM until the hot copy SM is restored).
During the period when the SM is not running, no scheduled journal backups will occur, so no PIT restorations will be possible for any transactions that occurred while the SM was down, even after it is running again and has brought itself up to date by SYNCing.
However, it is not usually necessary to back up all your SMs. In most domains there is a mixture of hot copy SMs (used for backup) and non-hot copy SMs (no backups taken).
| Unless you are using storage groups, do not run hot copy against more than one SM in the same command - see the example in the next section. |
Multi Zone Redundant Hot Copy
Suppose a domain consists of 2 or more regions, with at least 2 SMs in each region and that storage groups are not being used (hot copy with storage groups is covered below).
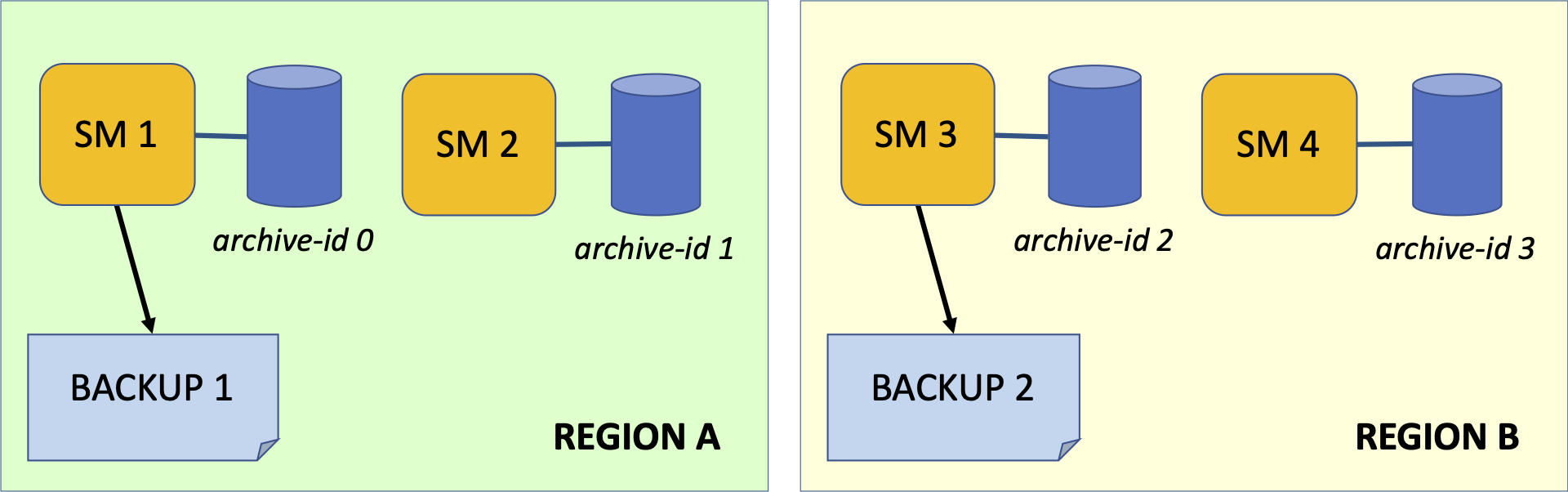
If a region fails, the processes in the other region(s) can continue ensuring database availability.
Similarly, hot copy backup should be performed against at least one SM in each region. If an SM is offline, the other(s) can still run hot copy.
| How many SMs and regions you need will depend on your requirements, this is just an example for discussion, not a recommendation. It is also important to maintain Process Majority across the regions. |
To backup the archives for multiple SMs, schedule each hot copy command separately:
nuocmd hotcopy database --db-name test --type full --backup-dirs 0 /backups/test-2021-12-18-archive-0nuocmd hotcopy database --db-name test --type full --backup-dirs 2 /backups/test-2021-12-18-archive-2-
The backup set directory name can be whatever you like; here it is derived from the database name, the creation date and the archive name.
-
The first command backs up archive with id=0 to
/backups/test-2021-12-18-archive-0. -
The second backs up archive with id=2 to
/backups/test-2021-12-18-archive-2. -
They can run concurrently if you wish, but doing so will place additional load on both SMs. The technique described in Interleaved Backups can also be used with full hot copy.
Although we want to run hot copy against two SMs, do not use a single command like this:
# DO NOT DO THIS ...
nuocmd hotcopy database --db-name test --type full --backup-dirs 0 /backups/2021-12-18-arch0 2 /backups/2021-12-18-arch2
Using --default-backup-dir and/or specifying multiple archives to --backup-dirs initiates a coordinated backup which requires extra work and overhead and is unnecesary unless using storage groups (see below).
|
Interleaved Backups
Incremental and journal backups should also be performed against multiple SMs and we recommend doing so in a staggered or interleaved manner.
For example, suppose you wish to run incremental backup hourly. Continuing the scenario above, run the incremental backup for archive 0 every two hours on even numbered hours, and the incremental backup for archive 2 for every odd numbered hour in between.
In this way, an incremental backup is taken every hour, even though a given archive is only backed up every two hours.
Journal backups typically occur more frequently, maybe every 15 minutes, and again can be staggered to achieve maximum coverage.
| How often you backup is entirely dependent on your RTO and RPO requirements. The backup periods quoted here are examples not recommendations. |
Redundant Hot Copy with Storage Groups
Implementing Table Partitions and Storage Groups typically means that no single SM archive contains the entire database. Instead each SM manages a subset of storage groups, reducing the amount of disk resources it needs and/or the load placed upon it.
In this setup, a coordinated hot copy is required, backing up several SMs simultaneously to ensure the backups together represent a transactionally consistent state.
Suppose each region in our domain now has three SMs and we have partitioned the database across three storage groups SG1, SG2 and SG3. Each SM manages two different storage groups ensuring redundancy if an SM fails.
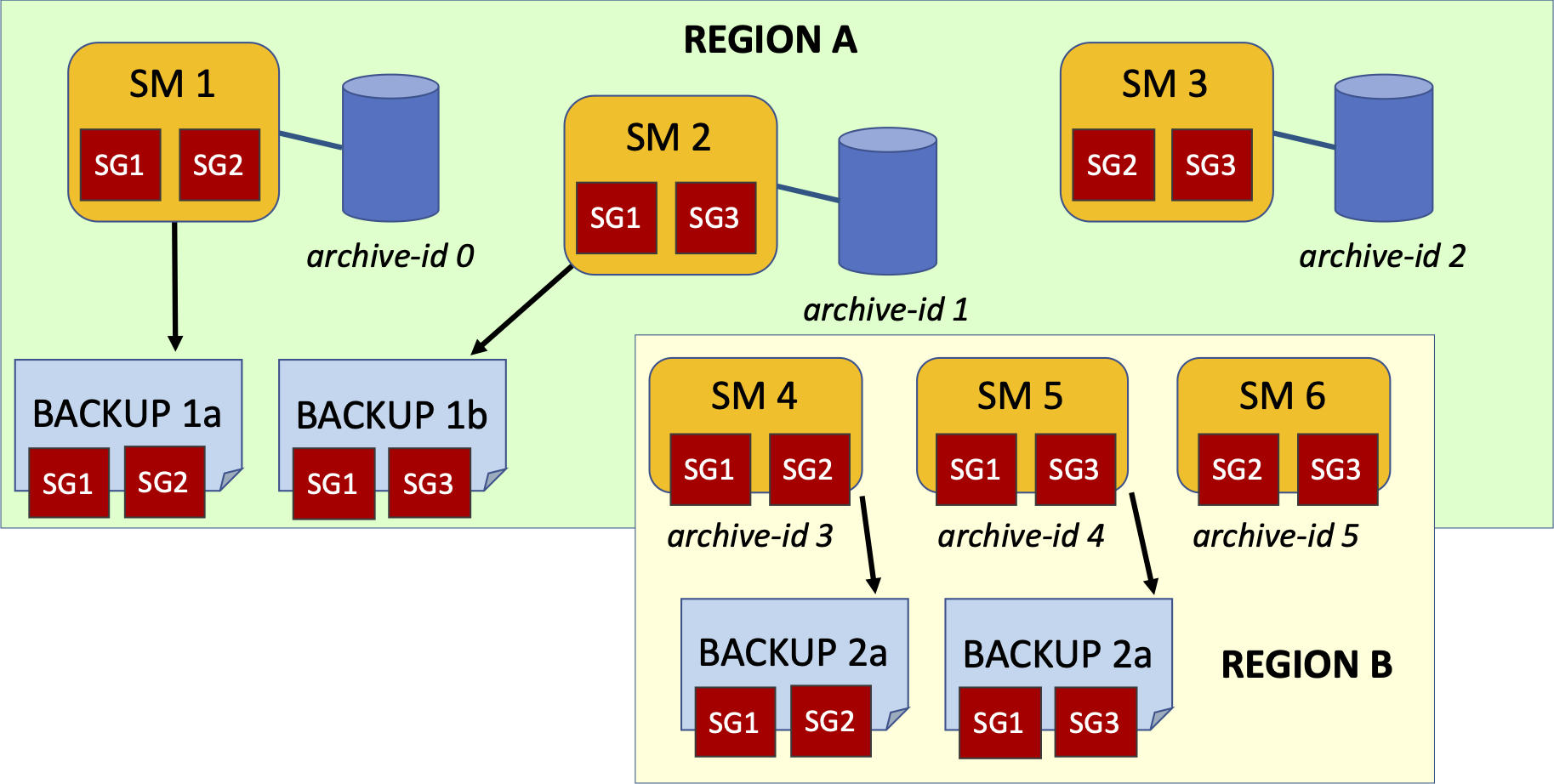
Backing up any one SM will only back up two of the three storage groups.
-
A coordinated hot copy backs up two or more SMs in such a way that the resulting hot copy is guaranteed to contain a transactionally consistent state.
-
A coordinated back up will involve multiple backup sets (one for each SM), referred to as a backup collection.
For example, backing up SM1 (archive id 0) and SM2 (archive id 1) together:
nuocmd hotcopy database --db-name test --type full --backup-dirs 0 /backups/2021-12-18-arch0 1 /backups/2021-12-18-arch1Note that since SM1 and SM2 both manage SG1, SG1 will be backed up twice, once by each of them. This is not a problem.
In region B, we would similarly backup SM4 and SM5 (archive ids 3 and 4) to ensure backup redundancy.
| Coordinated backup involves more work and should not be used unnecessarily. In the previous scenario, backing up one SM from each region with no storage groups, a coordinated backup is not required. Running each backup as a separate hot copy command is more efficient. |
When executing a hot copy request against a database configured with storage groups, it is required to select archives that include all database storage groups.
The NuoDB Admin will verify that the supplied backup locations include all storage groups configured for the database to prevent the user from creating an incomplete backup.
This validation can be disabled with the --partial-storage-groups flag for the nuocmd hotcopy database command.
The --partial-storage-groups flag should be used with caution as restoring from such a backup can lead to data loss due to missing storage groups.
The flag can be useful in cases where a storage group is temporarily unavailable but not yet deleted.
|